The following discussion of optimal acoustical environments is by Robert J. Doman Jr., Founder and Director of The National Academy for Child Development.
Optimal Acoustical Environments
To understand the significance of neurodevelopmental auditory training, we must look at an optimal acoustic environment for the developing brain and compare that to the realities of today. Keep in mind that initial auditory input for the unborn child far transcends the mere act of hearing: sound affects the entire well-being of the brain, mind, central nervous system, and body.
Optimally, the fetus is enveloped in an environment of natural tones consisting of the mother’s voice, her heartbeat and body sounds, and sounds from the environment transmitted through the mother’s body. In the best circumstances, external environmental sounds would include the voices of the father, siblings, and other family members, as well as the sounds of nature and nourishing music.
Following birth, the infant’s acoustic world would hopefully not change significantly. It would remain natural and pleasant, void of excessive harsh or loud sounds, and consist largely of lighter, natural high frequency sounds such as the wind blowing through trees, the sound of a babbling brook, or the song of a bird. Hopefully, this acoustic environment of the infant is relatively pure and free of extraneous sounds, particularly louder mechanical noise. This pure auditory environment would permit the brain to process individual tones, first within a comfortable frequency range, and then expanding as the system matures.
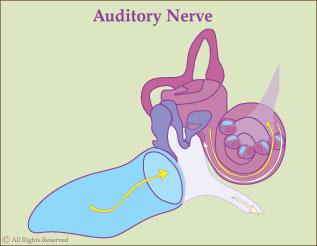
At birth the brain already hears; sound is transmitted as electro-chemical impulses to the brain. However, at this infantile stage, the brain must learn how to differentiate, interpret, and process individual tones. Later, these tones take on meaning as individual sounds, which are then grouped together and processed sequentially, eventually developing meaning as a language. The child’s brain does not do all this at birth—it merely receives unidentified and undifferentiated impulses.
A significant part of early auditory development is learning how to process the tones in language. It is generally felt that a child learns within the first two years how to process the specific tones in his or her native language. Without specific acoustic intervention, most individuals have difficulty learning to hear (and thus speak) another language if they have not been exposed to that language within the first few years of life.
Unfortunately, the realities of today’s world bear little resemblance to our optimal acoustic environment. Consider the contrast between two people talking in a meadow and today’s urban world. Compare the natural, positive neurodevelopmental acoustic environment with the destructive acoustic environments in which most of us live. It is almost impossible to find a place on the planet where one is not constantly assaulted by environmental noise pollution. This can result in adverse neurological, physiological, and psychological consequences. In our homes, disturbing sounds can include appliances, florescent lights, the traffic outside, and the mentally destructive thumping of the bass speakers on our teenager’s or neighbor’s sound system. Outside of the home, the assault only worsens: planes, trains, automobiles, power tools, and all of the negative acoustic trappings of our technological cultures. Even if one were fortunate enough to have spent the first few years of life in an acoustically favorable environment, the current environment would rapidly undo the positive aspects of that beginning.
Dr. Alfred Tomatis: An Expanded View of Sound
The following material on Dr. Alfred Tomatis is by Ron Minson, M.D., Co-producer of The Listening Program and Co-founder and Medical Director of The Center for Inner Change.
 Approximately fifty years ago, a young French doctor made a startling discovery. Alfred Tomatis, a surgeon specializing in matters of the ear, nose, and throat, clinically verified that people can only make sounds they can hear. In other words, if we cannot hear a sound, we cannot reproduce it. This theory has come to be internationally known and respected as the Tomatis Effect, and has established the link between hearing and speech. From this theorem, we now know that our ability to perceive sound affects our ability to communicate. The implications of this discovery are great. Voice and ear are inextricably linked; both are foundations of neurological, emotional, and social development. Proper auditory perception impacts our language skills and communication, which, as we know, is the basis of social development, self-confidence, and self-image.
Approximately fifty years ago, a young French doctor made a startling discovery. Alfred Tomatis, a surgeon specializing in matters of the ear, nose, and throat, clinically verified that people can only make sounds they can hear. In other words, if we cannot hear a sound, we cannot reproduce it. This theory has come to be internationally known and respected as the Tomatis Effect, and has established the link between hearing and speech. From this theorem, we now know that our ability to perceive sound affects our ability to communicate. The implications of this discovery are great. Voice and ear are inextricably linked; both are foundations of neurological, emotional, and social development. Proper auditory perception impacts our language skills and communication, which, as we know, is the basis of social development, self-confidence, and self-image.
Dr. Tomatis went on to investigate the impact of diminished hearing and found that numerous physiological and psychological functions are associated with impaired auditory function. Autism, learning disabilities, Meniere’s Syndrome, depression, and attention deficit disorder are but a few conditions affected by how we perceive sound.
Dr. Tomatis came to see sound as a nutrient for the nervous system. He pinpointed how the unborn child perceives sound by 16 weeks in utero, and went as far as to say that sound helps to grow the fetal nervous system. Research into the hearing mechanism leads us to the other end of the spectrum as well. The strapedius muscle—one of two tiny muscles that cantilever the bones of the middle ear—is the only muscle of the human body that never rests. It regulates sound perception until the moment the heart stops. Thus, unless there is pathological damage, we begin hearing prior to birth and continue processing sound day and night for as long as we live.
Dr. Tomatis laid out the framework for an expanded understanding of the ear and its function. In addition to identifying the pervasive impact of sound, Tomatis created a system for retraining the auditory mechanism that included sophisticated frequency filtration and gating techniques. It is therefore with great respect that we salute and acknowledge the man known as the Einstein of the Ear, whose insights provide the foundation upon which we build.